

第2回: 競馬予測に必要なデータ前処理
前回の振り返り
前回の記事では、Google Colab の環境構築からスクレイピングまでを行い、netkeiba から競馬のレース結果データを取得しました。
CSV ファイルを開いてみると、馬名や騎手名、タイム、着順など…様々なデータが並んでいます。
しかしながらこのデータ、そのままでは AI に学習させられません。
なぜ前処理が必要なのか
機械学習モデルは基本的に「数値」しか理解できません。「ディープインパクト」という馬名を見せても、AI には意味がわかりません。
前回取得したデータを見てみましょう。
- 馬名: 「ディープインパクト」「オルフェーヴル」…→ 文字列
- 性齢: 「牡 4」「牝 3」…→ 性別と年齢が混ざった文字列
- 馬体重: 「452(-4)」…→ 体重と増減が一緒になっている
- タイム: 「1:09.5」…→ 分と秒が混ざった文字列
これらを全て数値に変換する必要があります。
そして、もう一つ重要なのが特徴量エンジニアリング。「この馬の前走成績はどうだったか」「この騎手は最近調子がいいのか」といった、予測に役立ちそうな情報を計算して追加する作業です。
「Garbage In, Garbage Out」
これは機械学習でよく使われる言葉で、「ゴミを入れたらゴミが出てくる」という意味です。
どんなに高性能なモデルを使っても、入力データの質が悪ければ予測結果も悪くなります。
実は、モデル構築よりも前処理に費やす時間のほうが長い、というのがデータサイエンスの現実。
ここを丁寧にやるかどうかで、最終的な予測精度が大きく変わってきます。
- 生データを数値データに変換(クリーニング処理)
- 特徴量エンジニアリングで予測に役立つ変数を作成
- カテゴリ変数の One-Hot Encoding
- 日付の周期性を三角関数で表現
環境準備
まずは前回と同様に、必要なライブラリをインポートします。
!pip install japanize-matplotlib lxml
from google.colab import drive
import numpy as np
import pandas as pd
import os
import re
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
drive.mount("/content/drive")
BASE_DIR = "drive/MyDrive"
warnings.simplefilter("ignore")インストール後、前回保存したデータを読み込みます。
# データの読み込み
all_result = pd.read_csv(os.path.join(BASE_DIR, "all_result.csv"))
print(f"データ件数: {len(all_result)} 行")
all_result.head()Step 1: データクリーニング
着順の処理
まずは着順から見ていきましょう。データを見てみると、数字以外の値が混ざっていることがあります。
- 「中」→ 競走中止
- 「取」→ 出走取消
- 「失」→ 失格
- 「除」→ 除外
- 「(降)」「(再)」→ 降着や再騎乗の付記
これらは予測の対象外なので、削除または変換します。
df = all_result.copy()
# 無効な着順を除外
df = df[~df["着 順"].isin(["中", "取", "失", "除", np.nan])]
# (降)や(再)の付記を削除
df["着 順"] = (
df["着 順"]
.replace("\\(降\\)", "", regex=True)
.replace("\\(再\\)", "", regex=True)
.astype(int)
)
print(f"クリーニング後: {len(df)} 行")タイムの処理
タイムは「1:09.5」のような形式で、分:秒.コンマ秒 になっています。これを秒単位の数値に変換します。
# タイム処理: "."を":"に置換してから分割
df["タイム"] = df["タイム"].str.replace(".", ":")
# 分:秒:ミリ秒 に分割
time_split = df["タイム"].str.split(":", expand=True)
if time_split.shape[1] == 3:
df["分"] = time_split[0].astype(float)
df["秒"] = time_split[1].astype(float)
df["ミリ秒"] = time_split[2].astype(float)
# 秒単位に換算
df["タイム"] = df["分"] * 60 + df["秒"] + 0.1 * df["ミリ秒"]たとえば「1:09.5」は以下のように変換されます:
馬体重の処理
「452(-4)」のような形式を、体重と増減に分割します。
# 馬体重を分割
df[["体重", "体重増減"]] = (
df["馬体重"]
.str.replace(")", "")
.str.split("(", regex=False, expand=True)
.astype(float)
)str.split("(") で「452」と「-4」に分けて、それぞれ数値に変換しています。
性齢の処理
「牡 4」「牝 3」のような性齢は、性別と年齢に分離します。正規表現を使って抽出しましょう。
# 性齢を分割
df[["性", "年齢"]] = df["性齢"].str.extract(r"(牡|牝|セ)(\d+)", expand=True)
df["年齢"] = df["年齢"].astype(int)正規表現 (牡|牝|セ)(\d+) の意味:
(牡|牝|セ)→ 「牡」「牝」「セ(セン馬)」のいずれか(\d+)→ 1 つ以上の数字
単勝オッズの処理
単勝オッズにはカンマや「—」(データなし)が含まれていることがあります。
# 単勝オッズを数値化
df["単勝オッズ"] = (
df["単勝"].str.replace(",", "").replace("---", None).astype(float)
)不要な列の削除
処理が終わった元の列は削除しておきます。
# 不要な列を削除
cols_to_drop = [
"性齢", "着差", "単勝", "馬体重", "分", "秒", "ミリ秒"
]
df = df.drop(columns=[c for c in cols_to_drop if c in df.columns])Step 2: 特徴量エンジニアリング
クリーニングが終わったら、いよいよ特徴量エンジニアリングです。
「この馬の実力」を数値で表現するために、過去のデータから計算した指標を追加していきます。
ラグ特徴量: 前走成績
「前走で何着だったか」は、馬の調子を測る重要な指標です。

# 前走着順(ラグ特徴量)
df["1走前着 順"] = (
df.groupby(["馬名"])["着 順"]
.apply(lambda x: x.shift(1))
.reset_index(drop=True)
)groupby(["馬名"]) で馬ごとにグループ化し、shift(1) で 1 行ずらすことで「前走の着順」を取得しています。
なぜ shift(1) なのか?
機械学習では「未来の情報」を使って予測してはいけません(リークと呼ばれる問題)。
今回のレースの着順を予測するために、今回のレースのデータを使ってしまうと反則ですよね。
shift(1) で「1行前」=「過去のレース」のデータだけを参照するようにしています。
集約特徴量: 騎手の平均着順
騎手の実力も重要な要素。過去 20 レースの平均着順を計算します。
# 騎手の平均着順(移動平均)
df["平均着 順"] = (
df.groupby(["騎手"])["着 順"]
.apply(lambda x: x.shift().rolling(window=20, min_periods=1).mean())
.reset_index(drop=True)
)rolling(window=20) で過去 20 レース分の移動平均を計算。shift() を入れることで、やはり「過去のデータのみ」を使うようにしています。
One-Hot Encoding
「性別」や「騎手」のようなカテゴリ変数は、そのままでは機械学習モデルに入力できません。
One-Hot Encoding(ワンホットエンコーディング)という手法で、カテゴリ変数を 0/1 の数値に変換します。
# One-Hot Encoding
categorical_columns = ["性", "騎手"]
df = pd.get_dummies(
df,
columns=[c for c in categorical_columns if c in df.columns],
drop_first=True
)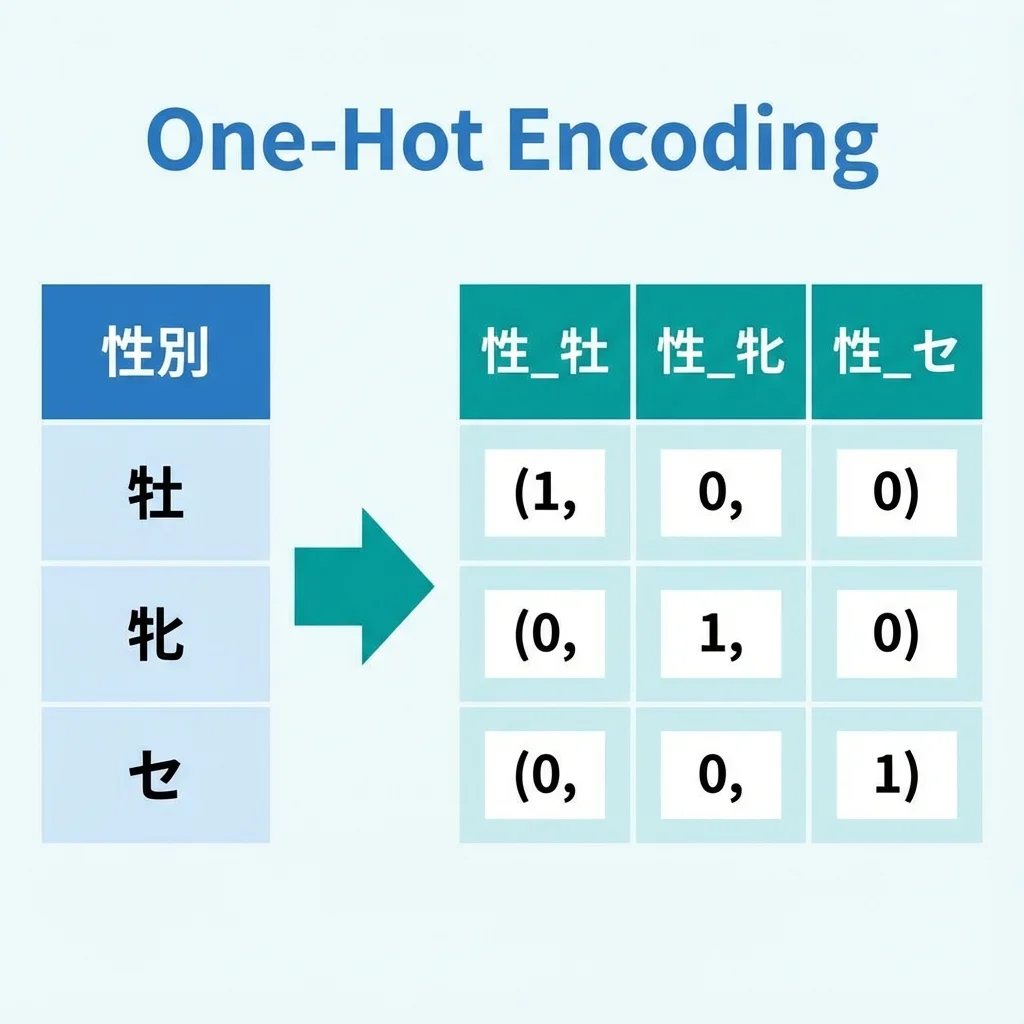
drop_first=True により「牡」は両方 0 で表現されます(情報の冗長性を避けるため)。
日付の周期性表現
最後に、日付の処理です。
1 月と 12 月は「数字上」は離れていますが、「季節」としては近いですよね。こういった周期性を表現するために、三角関数(sin/cos)を使います。
# 日付処理
if "日付" in df.columns:
df["日付"] = pd.to_datetime(df["日付"], format="%Y年%m月%d日")
df["月"] = df["日付"].dt.month
df["日"] = df["日付"].dt.day
# 月日を数値化 (1年を約365として正規化)
df["月日の数値"] = (df["月"] - 1) * 31 + df["日"]
# sin/cos変換で周期性を表現
df["sin日付"] = np.sin(2 * np.pi * df["月日の数値"] / 365)
df["cos日付"] = np.cos(2 * np.pi * df["月日の数値"] / 365)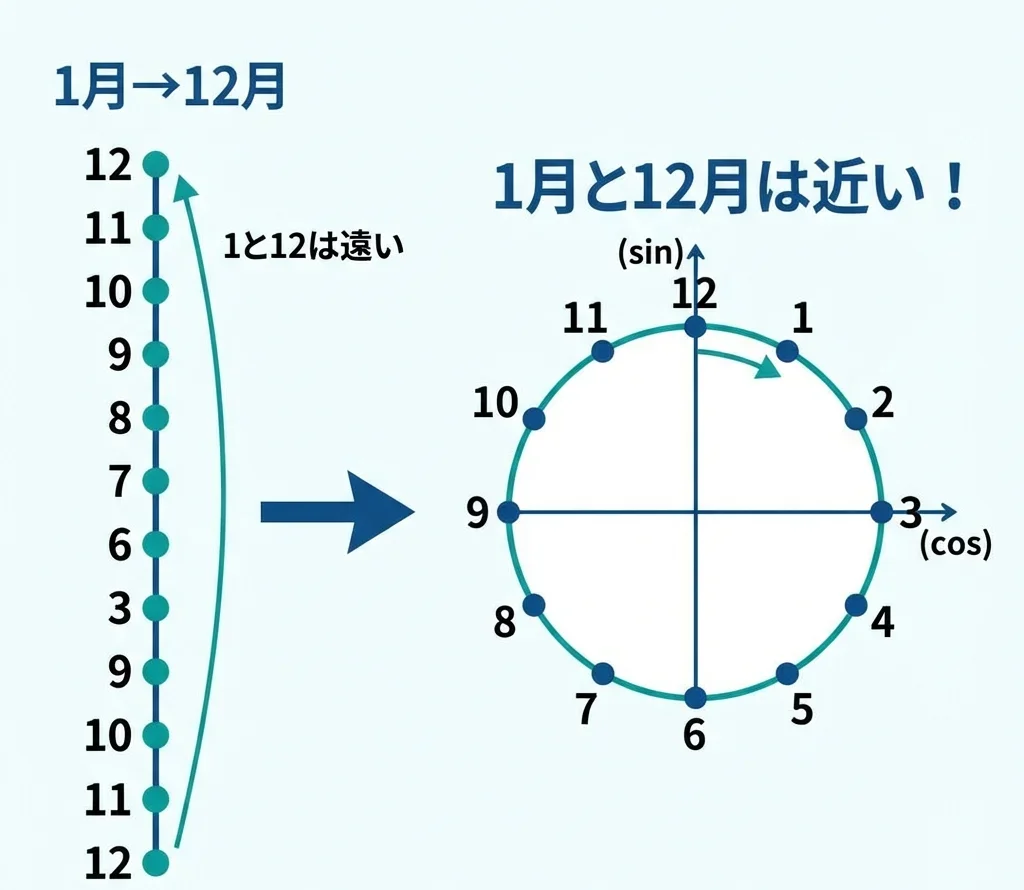
なぜこうするのか。1 月を「1」、12 月を「12」という数値で扱うと、AI には「12 は 1 より 11 大きい」としか理解できません。でも実際は、12 月と 1 月(翌年)は隣り合っています。
sin/cos 変換を使うと、円周上の座標として日付を表現できます。これで「12 月と 1 月は近い」という情報を AI に伝えられるんです。
さらに、日付をエンコードすることで季節性を捉えられるため、間接的に気温や降水量といった情報も反映できます。夏は暑く、冬は寒い。梅雨時期は雨が多く、秋は乾燥しやすい。これらの気象パターンは馬場状態や馬のパフォーマンスに影響するため、日付の周期的表現は思った以上に有用な特徴量になります。
学習に使わない列の削除
最後に、予測に直接使わない列を削除します。
# 学習に不要な列を削除
cols_to_drop = [
"馬名", "調教師", "レースID", "日付",
"月", "日", "月日の数値"
]
df = df.drop(columns=[c for c in cols_to_drop if c in df.columns])
# 保存
df.to_csv(os.path.join(BASE_DIR, "processed_all_result.csv"), index=False)
print(f"保存完了: {len(df)} 行, {len(df.columns)} 列")「馬名」を削除するのはもったいない気がしますよね。でも、馬名自体は予測には使えません。馬の実力は「過去の着順」や「タイム」といった数値で表現します。もし馬名をそのまま使うと、過去のレースにしか出ていない馬(引退馬など)のデータでしか学習できなくなってしまいます。
Step 3: データの確認
前処理が終わったら、データを可視化して確認してみましょう。
# 相関行列の可視化
plt.figure(figsize=(10, 8))
numeric_df = df.select_dtypes(include=[np.number])
corr = numeric_df.corr()
sns.heatmap(corr, annot=False, cmap='coolwarm', linewidths=0.5)
plt.title("特徴量の相関行列")
plt.show()
相関行列を見ると、各特徴量がどの程度関連しているかが分かります。
たとえば実際のデータでは、以下のような傾向が見られます:
- 着順と人気: 正の相関(人気がある馬ほど上位に来やすい)
- 着順と単勝オッズ: 正の相関(オッズが低い馬ほど着順が良い)
- 枠番と馬番: 強い正の相関(同じ情報を持つため)
- タイムと着順: 正の相関(速いほど上位)
強い相関がある特徴量は予測に役立つ可能性が高いですが、同時に多重共線性(似た情報の重複)に注意も必要です。たとえば「人気」と「単勝オッズ」はほぼ同じ情報を表しているため、両方をモデルに入れると過学習の原因になることがあります。
さらなる工夫
ここで紹介したのは、あくまで基礎的な前処理です。
実際に競馬予想の精度を上げようと思うと、もっと様々な特徴量を作り込む必要があります。たとえば…
- 血統情報: 父馬・母馬の成績傾向
- コース適性: その馬が得意な距離や馬場状態
- 調教データ: レース前の調教タイムや内容
- 天候・馬場情報: 雨の日の成績、芝/ダートの適性
- 展開予想: 逃げ馬が多いレースかどうか
こういった「ドメイン知識」に基づいた特徴量を追加していくことで、予測精度は向上していきます。
このブログで公開している予測は、今回紹介した以上の独自の特徴量エンジニアリングを行っています。企業秘密…とまでは言いませんが、ここは各自で工夫するところです。競馬に詳しくなることと試行錯誤することが、AI精度向上の重要ポイントです。
まとめ
今回は、前回取得した生データを機械学習モデルに入力できる形に変換しました。
- ✅ クリーニング: 無効データの除去、文字列の数値化
- ✅ 特徴量エンジニアリング: ラグ特徴量、集約特徴量の作成
- ✅ One-Hot Encoding: カテゴリ変数の数値変換
- ✅ 周期性表現: 日付の sin/cos 変換
地味な作業に見えますが、ここが AI 精度を左右する最重要工程。次回はいよいよ機械学習モデルの構築に入ります。
まずは解釈しやすいロジスティック回帰から始めて、「AI が何を見て予測しているのか」を確認していきましょう。