

AIの作り方④ディープラーニング入門!AIを支える技術の全貌
前回の記事「AIの作り方③競馬AI予測モデルの構築ガイド!初めてのモデル作成AIの作り方③競馬AI予測モデルの構築ガイド!初めてのモデル作成」では、分類・回帰の違いや評価方法、ロジスティック回帰の作り方についてお話ししました。今回はさらに発展してついに深層学習について解説します!深層学習と聞くとなんだか難しそうに聞こえますが、丁寧に解説しています。
ただし僕の専門分野で大ボリュームになってしまったので、コードは次回の記事「AIの作り方⑤流行りの深層学習を行うのは超簡単!競馬予想深層学習モデルの作り方」で公開しています。仕組みはおいといてとりあえず動かしてみたいという方はこの記事は読み飛ばしちゃってください!
はじめに:深層学習とは何か?
深層学習って何?
まず、「深層学習(ディープラーニング)」という言葉の意味から見てみましょう。深層学習とは、大量のデータから規則性や特徴を自動的に学び取る技術です。例えば、顔認識システムや音声アシスタント、さらにはNetflixやYouTubeのおすすめ機能も、深層学習のおかげで動いています。
この技術の中心にあるのが「ニューラルネットワーク」という数学モデルです。脳の神経細胞(ニューロン)の働きを模した構造を持ち、多層に重ねることで「深層」になるわけですね。この多層構造が、複雑なパターンを捉える能力を持つ秘訣なんです。
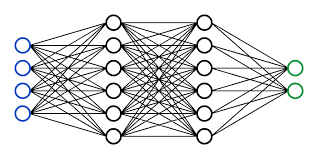
競馬予測と深層学習の関係
では、この深層学習を競馬予測に活用するとどうなるでしょう?競馬では、レース結果に影響を与える要素が非常に多いですよね。馬の成績、天候、騎手、レース距離など、人間が全てを直感や経験で分析するには限界があります。
深層学習を使えば、これらの複雑な要因を統計的に解析し、「どの馬が有利か」というパターンを発見できます。特に、データ量が多ければ多いほどその威力を発揮します。過去のレース結果や馬の特徴を活用して予測モデルを作成することで、これまで以上に精度の高い予測が可能になるのです。
深層学習が身近になる理由
「でも、それって専門家じゃないと無理なんじゃないの?」と思った方、ご安心ください!近年、深層学習を使いやすくするためのツールやライブラリが充実しています。Pythonを使えば、難しい数式や理論を知らなくても簡単にモデルを構築できるんです。
たとえば、Googleが提供する「TensorFlow」やFacebookが開発した「PyTorch」などのフレームワークを使えば、直感的に深層学習を始めることができます。この記事では、競馬データを使った具体的なモデルの作り方を解説するので、ぜひ挑戦してみてください!
競馬予測における深層学習の利点
従来の機械学習手法と比較すると、深層学習は予測精度の向上や柔軟な適応性において非常に大きなメリットを持っています。このセクションでは、競馬予測に深層学習を採用する利点をいくつかのポイントに分けてわかりやすく解説します。
複雑なパターンの発見が得意
競馬のレース結果は、馬の過去の成績、騎手、天候、馬場状態、さらにはレース当日の気温など、膨大で複雑な要因によって決まります。従来の手法では、これらの要因を一つ一つ分析して特徴量として設計する必要がありましたが、深層学習はこれらを一度に処理する能力を持っています。
例えば、ある馬が雨の日に強い傾向があるとしても、その傾向が馬場状態や騎手のスキルと組み合わさった場合にどのような影響を及ぼすかを従来の手法で正確に捉えるのは困難でした。しかし、深層学習はこれらの複雑な相互関係を自動で解析し、予測モデルに反映させることができます。この能力により、予測精度を大きく向上させることが可能です。
高い柔軟性と適応性
深層学習は、新しいデータや環境への適応が得意です。例えば、競馬予測であれば、レース条件や新たな馬の情報が追加された場合でも、その変化に対応したモデルを簡単に再訓練することができます。
また、競馬特有の要因だけでなく、画像データ(たとえば馬の写真)やテキストデータ(専門家の予想コメント)といった異なる形式のデータも扱える点が大きな利点です。この柔軟性により、競馬以外のさまざまな分野のデータも組み合わせて使用することが可能となり、さらなる精度向上が期待できます。
従来の手法との比較での優位性
従来の機械学習手法では、モデルにデータを入力する前に「特徴量」というものを設計する必要がありました。たとえば、「過去5レースの平均順位」「馬場状態の指数」などの具体的な指標を人間が決める作業です。しかし、このプロセスには以下のような問題点がありました:
- 専門知識が必要
競馬や統計学に詳しくないと、有効な特徴量を作成するのは困難です。 - 時間がかかる
膨大なデータをもとに、試行錯誤しながら特徴量を選ぶ必要があります。 - 最適化の難しさ
設計した特徴量が不適切だと、モデルの性能が大幅に低下するリスクがあります。
深層学習では、これらの問題が一気に解消されます。モデルがデータをそのまま入力として受け取り、自動的に重要なパターンを学び取るため、初心者でも高度な予測モデルを作成できるのです。
モデル構造を工夫できる
深層学習の大きな魅力は、モデル構造を自由にカスタマイズできる点です。たとえば、馬の過去成績やレース条件を処理するための層を追加したり、画像認識用の層を加えたりと、用途に応じてモデルを設計できます。
さらに、近年ではトランスフォーマーや畳み込みニューラルネットワーク(CNN)など、さまざまな高度なアーキテクチャが登場しており、これらを組み合わせることで、さらに高性能なモデルを構築することが可能です。
目的変数が自由
競馬予測における深層学習のもう一つの利点は、予測の目的変数を柔軟に設定できる点です。たとえば、「1着になる確率」だけでなく、「走破タイム」や「払戻金の期待値」といった多様な予測目標を設定できます。これにより、競馬ファンのニーズや戦略に合わせた独自の予測を提供することが可能になります。
深層学習モデルの構築手順
それでは、深層学習の中身を詳細に解説していきます!
データの準備と目標
それでは、深層学習モデルを構築する手順について詳しく解説していきます!
ここでは、すでにAIの作り方③競馬AI予測モデルの構築ガイド!初めてのモデル作成で使用した同じデータと目的変数を基に説明を進めます。具体的には、以下の内容を実現するモデルを構築します:
- 入力データ:馬のスピード、騎手の経験、天候、コース適正などの特徴量(テーブルデータ)。
- 目的変数(出力):その馬が三着以内に入るかどうか(バイナリ分類)。
モデルの設計
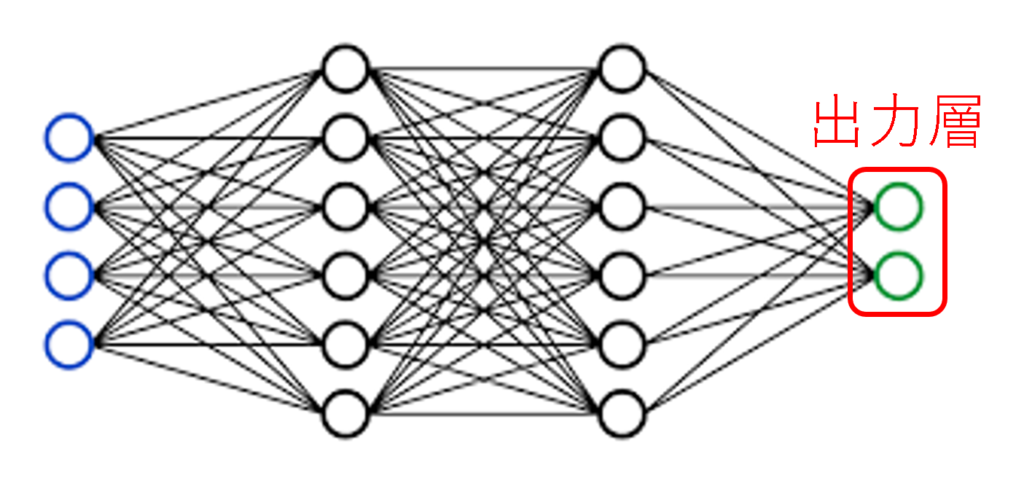
モデルは大きく分けて3つの部分に分かれています:
- 入力層:データを受け取る部分
- 中間層(隠れ層):データをもとに学習する部分
- 出力層:予測結果を出す部分
これを「データがどのように流れるか」に例えると、以下のようなイメージです:
入力層がデータを受け取り、
中間層でデータを処理し、
出力層が結果を計算して出します。
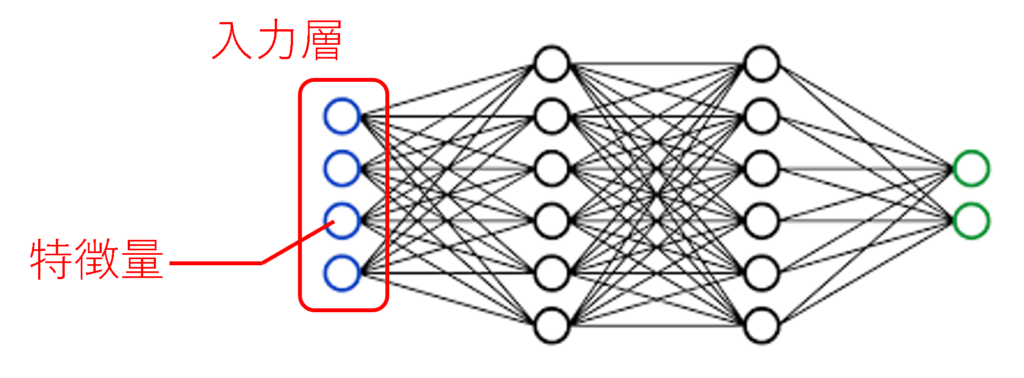
入力層
入力層は、データをモデルに送り込む部分です。競馬予測では、例えば以下のような数値データを使います:
- 馬の体重:500kg
- レース距離:1600m
- 人気:3位
など。
これらを「特徴量」と呼びます。
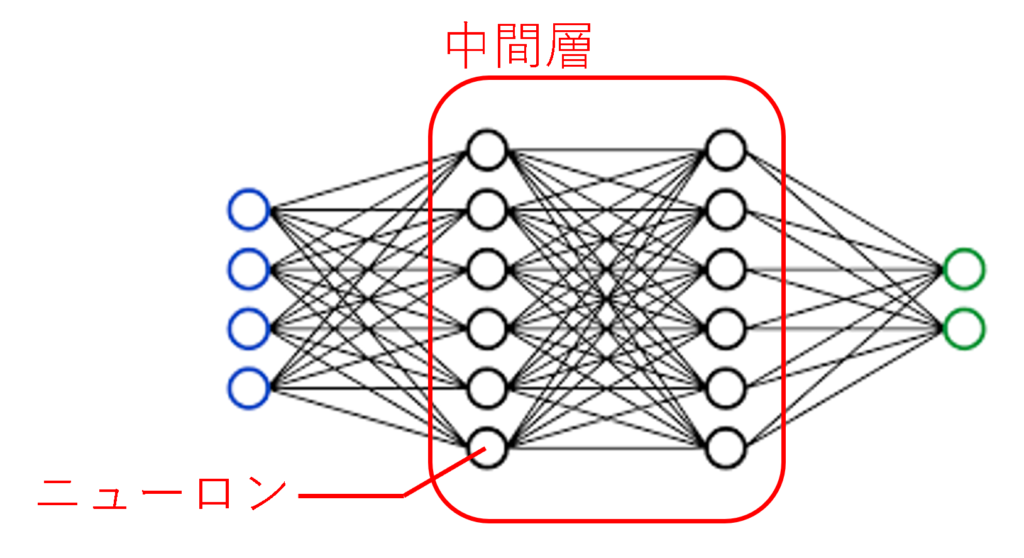
中間層(隠れ層)
中間層は、モデルが「特徴量の中にある隠れたパターン」を見つける部分です。この層が深層学習の「頭脳」にあたります。
- 中間層は「ニューロン」という小さな計算ユニットで構成されています。
- 各ニューロンがデータを受け取り、計算を行い、次の層に渡します。
ニューロンは、データをそのまま渡すのではなく、活性化関数を使って変換します。この変換により、モデルはデータの複雑な関係を学習できます。
よく使われる活性化関数
ReLU(Rectified Linear Unit):簡単で高速、競馬予測など多くの場面で使われます。
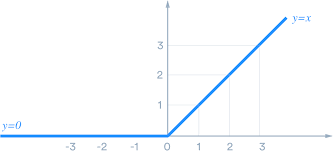
- 数式:\(f(x)=\max(0, x)\)
- 負の値は「0」に変換し、正の値はそのまま通します。
- 例:
- 入力:−2,3,0
- 出力:0,3,0
ドロップアウト
中間層には、ドロップアウトという技術を取り入れることもあります。
- 目的:モデルが「特定のデータに依存しすぎる(過学習する)」のを防ぐ。
- 仕組み:ニューロンの一部をランダムに無効化して学習させる。
隠れ層の数と構造
中間層の「層数」や各層の「ニューロンの数」は自由に設定することができます。次々回の記事では、より性能の良いモデルを試行錯誤します。
ただし、自分でモデルを変えるのも良い勉強になるので、ぜひ次回記事のサンプルコードのパラメータ部分をいじってみてください!
出力層
出力層は、モデルが最終的な答えを出す部分です。
出力例
競馬予測では、「その馬が三着以内に入る確率」を計算します。
- 出力値:確率(0~1の範囲)
活性化関数
シグモイド関数 を使います。
- 数式:\(\sigma(x) = \frac{1}{1 + e^{-x}}\)
- 出力値が 0~1 に変換されます。
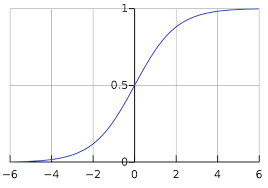
判断基準
- 出力値が 0.5以上 → 「三着以内」と予測
- 出力値が 0.5未満 → 「三着以内ではない」と予測
モデルの学習方法
AIモデルの学習は、「たくさんのデータを使って、正しい予測ができるようにする作業」です。
これは、スポーツや楽器の練習と同じで、「間違いを減らす」ことを繰り返しながら、精度を上げていきます!
学習の流れ(3つのステップ)
モデルの学習は、次の3つのステップで進みます。
- 予測する(フォワードプロパゲーション)
→ データを入力して結果を出す - 間違いを計算する(損失関数)
→ 予測がどれくらいズレているか計算する - 間違いを減らす(バックプロパゲーション + 最適化)
→ モデルのパラメータを調整して、精度を上げる
この流れを 何度も繰り返す ことで、モデルはどんどん賢くなります!
① 予測する(フォワードプロパゲーション)
まず、モデルは データを入力して予測 します。今回は「この馬は3着以内に入るか?」を予測します。
- 入力(馬の特徴)
- 体重:500kg
- レース距離:1600m
- 人気順位:3位
- 出力(予測結果)
- 0.7(=70%の確率で3着以内)
このように、入力データを元にモデルが計算し、確率や数値を出します。
② 間違いを計算する(損失関数)
次に、「予測結果」と「本当の結果」を比べて、どれくらい間違っているかを数値化します。
これを 損失(Loss) といい、損失関数で計算します。
例えば:
- 予測:0.7(70%)
- 実際の結果:1(本当に3着以内だった!)
→ 間違いが少ない(損失が小さい) - 予測:0.2(20%)
- 実際の結果:1(本当に3着以内だった!)
→ 間違いが大きい(損失が大きい)
損失が小さいほど、モデルの予測は正確ということになります!
よく使われる損失関数:バイナリクロスエントロピー
損失関数は、問題の種類によって使い分けます。
競馬AIの場合は「3着以内かどうか(0 or 1)」を予測する 分類問題 なので、バイナリ分類用の損失関数 を使います。
競馬予測のように「3着以内(1)or 圏外(0)」を予測する場合、
最もよく使われる損失関数が バイナリクロスエントロピー です!
計算式は、次のようになります:
\[Loss = -(y\log(p)+(1-y)\log(1-p))\]
- \(y=\)本当の結果(1: 3着以内 / 0: 圏外)
- \(p=\)モデルの予測値(0〜1の確率)
③ 間違いを減らす(バックプロパゲーション + 最適化)
モデルが賢くなるためには、予測の間違い(損失)を減らしていく必要があります。
そのために使われるのが バックプロパゲーション(誤差逆伝播) と 最適化アルゴリズム(オプティマイザー) です!
バックプロパゲーション(誤差逆伝播)
各ニューロンには 「重み(weight)」と「バイアス(bias)」 というパラメータがあり、これを調整することで予測の精度を上げます。
バックプロパゲーションでは、次のような流れで間違いを修正します:
- 損失を計算する
例:モデルの予測が「0.2(3着以内の確率20%)」だったが、実際は3着以内(1.0)だった場合、損失が大きい。 - 間違いの影響を逆方向に伝える(誤差逆伝播)
「どの層のどのニューロンが間違いの原因だったのか?」を計算し、それぞれの重みを調整する必要がある。 - 修正すべき方向を決める(勾配計算)
「このニューロンの重みを増やせば、次回の予測が良くなる!」という情報を取得する。
最適化(オプティマイザー)
バックプロパゲーションで「どのパラメータを修正すればいいか?」は分かりました。
しかし、「どれくらい修正すればいいのか?」を決めるのが 最適化アルゴリズム(オプティマイザー) です!
最適化アルゴリズムは、損失を小さくするために、重みやバイアスをどの方向にどれくらい変更するか? を決めます。
よく使われるオプティマイザーを紹介します!
- 勾配降下法(Gradient Descent)
最も基本的な方法で、次のように 少しずつ損失を減らしていく 仕組みです。
\[w = w – \eta \frac{\partial L}{\partial w}\]- \(w\)=調整したい重み
- \(\eta\)=学習率(learning rate):どれくらい更新するかの大きさ
- \(\frac{\partial L}{\partial w}\)=損失の勾配(どれくらいズレているか?)
- Adam(Adaptive Moment Estimation)
競馬予測などの実践では 「Adam」 という最適化アルゴリズムがよく使われます。
Adamは、単純な勾配降下法よりも 素早く・安定して学習 できるのが特徴です!
この流れを何度も繰り返す!(エポック学習)
AIモデルは 1回の学習 ではまだ完璧に予測できません!
そのため、 「予測 → 間違いを計算 → 修正」 を何度も繰り返すことで、徐々に精度を上げていきます。
この繰り返しの単位を 「エポック(Epoch)」 といいます!
また学習の際、バッチ学習という工夫を行います!
① エポック(Epoch)とは?
機械学習では、すべてのデータを1回学習することを 1エポック(1回の学習サイクル) といいます。
でも、1回だけではうまく学習できないので 何十回、何百回と繰り返し学習 します!
✅ 1エポック目:「まだ予測がズレている…」
✅ 2エポック目:「少し修正できた!」
✅ 10エポック目:「かなり精度が上がった!」
イメージ:スポーツの練習と同じ!
1回練習しただけでは上手くならないので、何度も練習して上達していくのと同じです!
どのくらいのエポック数が必要?
- エポック数が 少なすぎる と、まだ学習が足りない状態(アンダーフィッティング)になる
- エポック数が 多すぎる と、データに過剰に適応しすぎてしまう(オーバーフィッティング)
そのため、 検証データ(テストデータ)でモデルの精度を確認しながら、適切なエポック数を決める のがポイントです!
②バッチ学習とは?(データを小分けに学習!)
もしも 100万件 のデータを一度に学習しようとすると「メモリが足りなくて計算できない!」 という問題が発生します!
そこで、 データを小分けにして少しずつ学習 するのが バッチ学習 です!
- バッチサイズ = 一度に学習するデータの数
- バッチサイズ = 32 → 1回の学習で 32個 のデータを使う
- バッチサイズ = 100 → 1回の学習で 100個 のデータを使う
バッチサイズが大きいと…
✅ 1回の学習で 安定した更新 ができる
❌ でも 計算コスト(メモリ使用量)が大きくなる
バッチサイズが小さいと…
✅ メモリ消費が少なくて済む
❌ でも 学習が不安定(ばらつきが大きい) になる
まとめ
今回は、深層学習を活用した競馬予測について解説しました。深層学習の基本を押さえながら、競馬データに適用する方法を具体的に紹介しました。
深層学習を使うことで、馬の過去成績や騎手、天候など多様な要因を統合的に解析し、より精度の高い予測が可能になります。また、特徴量を手作業で設計する必要がなく、モデルが自動で重要なパターンを学習できる点も大きなメリットです。
記事では、モデル設計、学習・評価までの流れを説明しました。
次回は、実際にPythonを使って競馬予測の深層学習モデルを構築し、動かしてみます。実践的な内容になるので、ぜひお楽しみに!