

第1回: AIの基本とデータ収集
はじめに
「AIで競馬予想ができたら面白そう」——そう思ったことはありませんか。
最近は「機械学習」とか「ディープラーニング」といった言葉をよく耳にするようになりました。でも、いざ自分で作ろうとすると「高いPCが必要なんじゃ…」「プログラミングなんて無理…」と、ハードルが高く感じてしまいますよね。
ブラウザさえあれば、今すぐ始められます。
この連載では、Google Colab という無料ツールを使って、競馬予想AIをゼロから一緒に作っていきます。必要なのはGoogleアカウントだけ。ハイスペックなPCも、面倒な環境構築も不要です。
今回は第1回。まずは「AIに学習させるためのデータ」を集めるところからスタートしましょう。
- Google Colabの環境を構築する
- Google Driveをマウントして、データを永続保存できるようにする
- 競馬サイトからレース結果データをスクレイピングし、CSV形式で保存する
Google Colabとは?
Google Colabは、Googleが無料で提供しているクラウド上のPython実行環境です。
普通、Pythonを動かすには自分のPCに色々なソフトをインストールする必要があります。でもColabなら、ブラウザでアクセスするだけでPythonが使える。しかもGoogleのサーバーで処理が行われるので、自分のPCのスペックは関係ありません。
古いノートPCでも、ネットカフェのPCでも、同じように機械学習の実験ができます。
Colabの注意点:データは消える
ただし、一つ重要な注意点があります。
Colabは「一時的な」環境なので、時間が経つとデータが消えてしまいます。せっかく何時間もかけて集めたデータが、ランタイムの切断で全部パー…なんて悲劇は避けたいです。
そこで登場するのがGoogle Drive連携です。Colabから直接Google Driveにファイルを保存できるので、データを恒久的に保管できます。
環境構築
Step 1: Google Colabにアクセス
まずは Google Colab にアクセスして、新しいノートブックを作成します。Googleアカウントでログインしていれば、すぐに使えます。
Step 2: まずはシンプルなコードを実行してみる
Colabの使い方に慣れるため、簡単なコードを実行してみましょう。
新しいノートブックを開くと、空のセルが表示されます。このセルにPythonコードを入力して、左側の再生ボタン(▶)をクリックするか、Shift + Enter を押すと実行できます。
print("Hello, Colab!")セルの下に Hello, Colab! と表示されれば成功です。
もう少し試してみましょう。新しいセルを追加して(+ コードボタン)、計算を実行してみます。
# 簡単な計算
a = 10
b = 3
print(f"{a} + {b} = {a + b}")
print(f"{a} × {b} = {a * b}")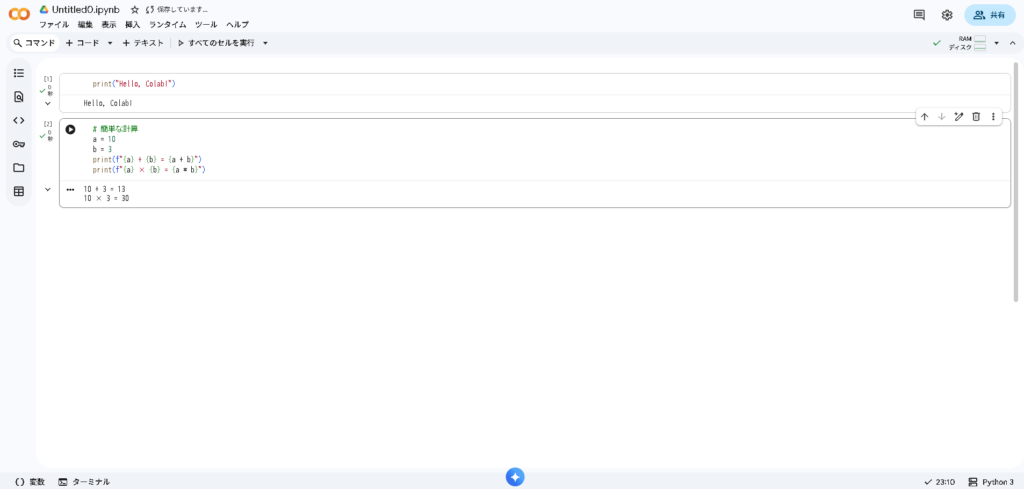
このように、セルにコードを書いて実行する、というのがColabの基本的な使い方です。
Step 3: 必要なライブラリのインストール
Colabには主要なライブラリがプリインストールされていますが、いくつか追加でインストールが必要なものがあります。以下のコードをセルに貼り付けて実行してください。
!pip install japanize-matplotlib lxml! から始まるコマンドは「シェルコマンド」と呼ばれ、Pythonではなくシステムに対する命令です。pip install はPythonのパッケージ管理ツールで、ライブラリをインストールするときに使います。
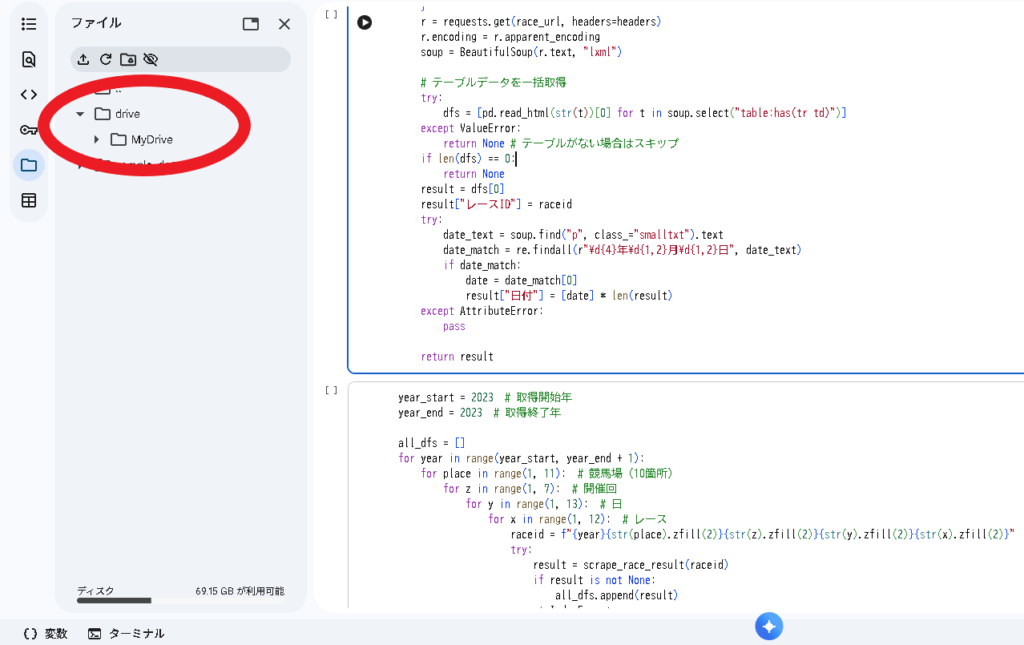
Step 4: Google Driveのマウント
次に、Google DriveをColabから読み書きできるようにします。以下のコードを実行すると、認証画面が表示されます。
from google.colab import drive
drive.mount('/content/drive')画面の指示に従って、Googleアカウントへのアクセスを許可してください。成功すると、/content/drive/MyDrive/ というパスでGoogle Driveにアクセスできるようになります。
マウント後は、左側のファイルブラウザに drive フォルダが表示されます。ここからGoogle Drive内のファイルを確認できます。
スクレイピングとは?
さて、いよいよデータ収集です。
競馬AIを作るには、過去のレース結果データが必要です。誰が何着だったか、タイムはどうだったか、オッズは…といった情報ですね。
こういったデータはWebサイトに公開されていますが、手作業でコピペするのは現実的ではありません。そこで使うのがスクレイピングという技術です。
スクレイピングとは、Webページから自動的にデータを抽出する技術のこと。プログラムでページにアクセスし、欲しい情報だけを取り出します。
スクレイピングを推奨しているわけではありません
本記事ではAI作成の学習目的でスクレイピングを紹介していますが、以下の点に注意してください:
- Webサイトの利用規約を必ず確認すること
- サーバーに過度な負荷をかけないこと(待機時間を設ける)
- 商用利用の場合は特に慎重に(データの権利関係を確認)
- 可能であれば公式APIや有料データサービスの利用を検討すること
スクレイピングによるトラブルについて、本ブログは一切の責任を負いません。自己責任でお願いします。
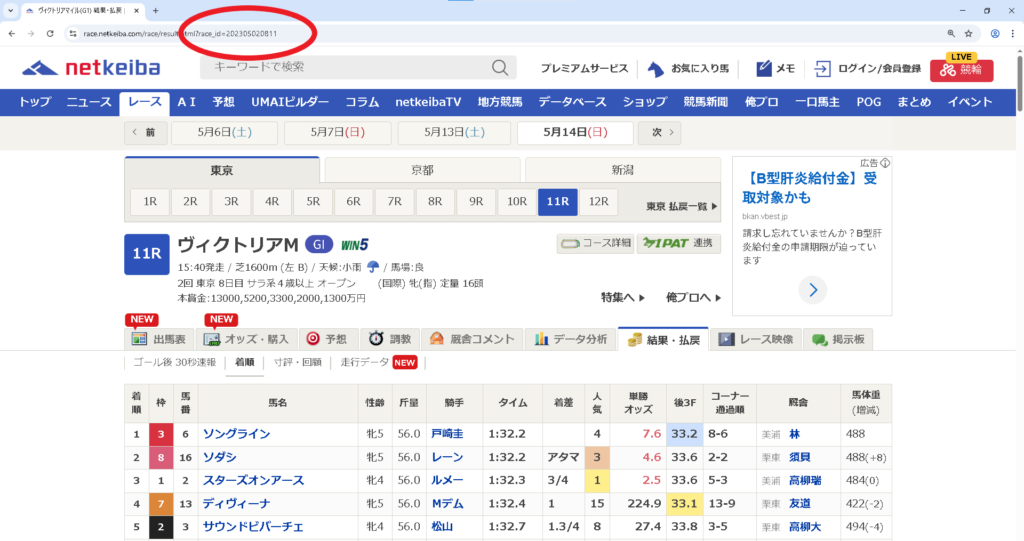
レースIDの仕組み
今回データを取得するのは db.netkeiba.com というサイトです。このサイトでは、各レースに12桁のレースIDが割り当てられています。
レースID = YYYY + PP + KK + DD + RR| 桁 | 意味 | 例 |
|---|---|---|
| YYYY | 年 | 2023 |
| PP | 競馬場コード (01~10) | 05 (東京) |
| KK | 開催回 (01~06) | 02 (第2回) |
| DD | 開催日 (01~12) | 08 (8日目) |
| RR | レース番号 (01~12) | 11 (第11レース) |
つまり、202305020811 というIDは「2023年・東京競馬場・第2回開催・8日目・第11レース」を表しています。
この規則性を利用すれば、ループ処理で大量のレースIDを自動生成し、連続してデータを取得できます。
スクレイピングのコード
いよいよ本番のコードです。まずはライブラリをインポートします。
import requests
import pandas as pd
import time
import re
import os
from bs4 import BeautifulSoup
# Google Driveの保存先
BASE_DIR = "drive/MyDrive"各ライブラリの役割を簡単に説明しておきます。
| ライブラリ | 役割 |
|---|---|
requests | Webページにアクセスしてデータを取得 |
pandas | データの表形式での操作 |
time | 待機処理(sleep)で使用 |
re | 正規表現(文字列パターンマッチ) |
os | ファイルパス操作 |
BeautifulSoup | HTML解析ライブラリ |
DataFrameとは
pandasの中心的なデータ構造で、Excelのスプレッドシートのようなものです。
行と列からなる表形式でデータを扱えます。本記事では、スクレイピングで取得したレース結果を
DataFrameとして保存・操作していきます。
スクレイピング関数の定義
続いて、1レース分のデータを取得する関数を定義します。
def scrape_race_result(raceid):
race_url = f"https://db.netkeiba.com/race/{raceid}"
time.sleep(5) # サーバー負荷軽減のため必ず待機
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
r = requests.get(race_url, headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "lxml")
# テーブルデータを一括取得
try:
dfs = [pd.read_html(str(t))[0] for t in soup.select("table:has(tr td)")]
except ValueError:
return None # テーブルがない場合はスキップ
if len(dfs) == 0:
return None
result = dfs[0]
result["レースID"] = raceid
# 日付の抽出
try:
date_text = soup.find("p", class_="smalltxt").text
date_match = re.findall(r"\d{4}年\d{1,2}月\d{1,2}日", date_text)
if date_match:
date = date_match[0]
result["日付"] = [date] * len(result)
except AttributeError:
pass
return resultコードはシンプルです。やっていることを順番に見ていきましょう。
コードの解説
1. URLの生成とアクセス
race_url = f"https://db.netkeiba.com/race/{raceid}"
time.sleep(5) # サーバー負荷軽減のため必ず待機f"https://.../{raceid}"— f文字列と呼ばれる書き方。{raceid}の部分に変数の値が埋め込まれますtime.sleep(5)— 5秒間待機。サーバーへの負荷を抑えるために必須です
time.sleep(5) は省略しないでください
スクレイピングはサーバーに負荷をかける行為です。短時間に大量アクセスすると、
サーバーに迷惑がかかるだけでなく、アクセス拒否される可能性もあります。
これはスクレイピングの最低限のマナーです。
2. リクエストヘッダの設定
headers = {
"User-Agent": "Mozilla/5.0 ..."
}
r = requests.get(race_url, headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "lxml")headers— リクエストヘッダ。Webブラウザからのアクセスを模倣します。これがないとアクセス拒否されることがありますrequests.get(url, headers)— 指定したURLにアクセスし、HTMLを取得r.encoding = r.apparent_encoding— 文字化け対策。日本語が正しく表示されるようになりますBeautifulSoup(r.text, "lxml")— 取得したHTMLを解析可能なオブジェクトに変換
3. テーブルデータの取得
try:
dfs = [pd.read_html(str(t))[0] for t in soup.select("table:has(tr td)")]
except ValueError:
return Noneこの部分がポイントです。
soup.select("table:has(tr td)")— CSSセレクタでテーブル要素を探しますpd.read_html(str(t))[0]— pandasの便利な関数で、HTMLのテーブルをDataFrameに変換してくれますtry-except— テーブルがないページでもエラーで止まらないようにしています
4. レースIDと日付の追加
result["レースID"] = raceid
try:
date_text = soup.find("p", class_="smalltxt").text
date_match = re.findall(r"\d{4}年\d{1,2}月\d{1,2}日", date_text)
if date_match:
result["日付"] = [date] * len(result)result["レースID"] = raceid— どのレースのデータか後で分かるようにIDを追加re.findall(...)— 正規表現で日付パターン(例:「2023年11月26日」)を抽出2026/06/04 * len(result)— 全ての行に同じ日付を入れるため、リストを行数分複製
データ収集の実行
では、実際にデータを収集してみましょう。以下のコードは2023年の全レースデータを取得する例です。
year_start = 2023 # 取得開始年
year_end = 2023 # 取得終了年
all_result = []
for year in range(year_start, year_end + 1):
for place in range(1, 11): # 競馬場 (10箇所)
for z in range(1, 7): # 開催回
for y in range(1, 13): # 日
for x in range(1, 12): # レース
raceid = f"{year}{str(place).zfill(2)}{str(z).zfill(2)}{str(y).zfill(2)}{str(x).zfill(2)}"
try:
result = scrape_race_result(raceid)
if result is not None:
all_result.append(result)
except IndexError:
continue
except Exception as e:
continue
# 結果の結合と保存
if all_result:
all_result = pd.concat(all_result)
all_result.to_csv(os.path.join(BASE_DIR, "all_result.csv"), index=False)
print(f"保存完了: {len(all_result)} 行")コードの解説
ループの構造
5重ループで全てのレースIDパターンを生成しています。
for year (2023~2023) → 1パターン
for place (1~10) → 10パターン(競馬場)
for z (1~6) → 6パターン(開催回)
for y (1~12) → 12パターン(日)
for x (1~11) → 11パターン(レース)合計: 1 × 10 × 6 × 12 × 11 = 7,920パターン
ただし、全てのパターンにレースが存在するわけではありません。存在しないIDにアクセスするとエラーになりますが、try-exceptで処理を続行します。
結果の保存
if all_result:
all_result = pd.concat(all_result)
all_result.to_csv(os.path.join(BASE_DIR, "all_result.csv"), index=False)pd.concat()— 複数のDataFrameを縦方向に結合to_csv(..., index=False)— CSVファイルとして保存(行番号は不要なのでFalse)
1年分のデータ収集には数時間~半日以上かかります
time.sleep(5) があるため、1レースあたり最低5秒。
7,920パターン × 5秒 = 約11時間(全てにレースがあった場合)。
最初はテスト用に place の範囲を range(1, 2) に絞るなど、
小さな範囲で動作確認してから本番を実行してください。
取得したデータを確認
データが保存できたら、中身を確認してみましょう。
import pandas as pd
df = pd.read_csv(os.path.join(BASE_DIR, "all_result.csv"))
print(df.shape) # (行数, 列数) を表示
df.head() # 最初の5行を表示成功していれば、以下のようなデータフレームが表示されます。
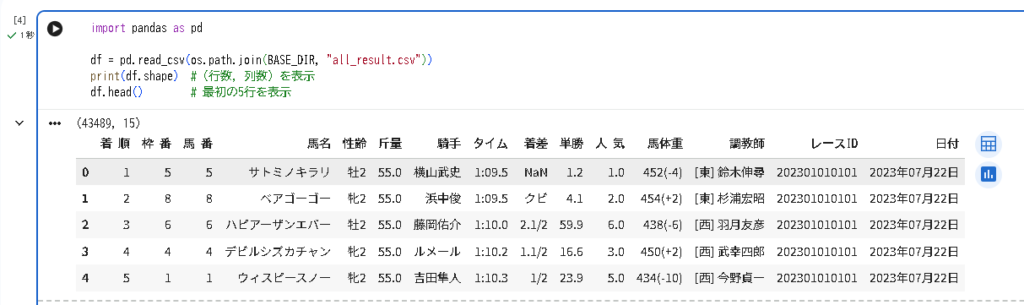
これが「生のデータ」です。着順、馬名、タイム、騎手など、レース結果の様々な情報が含まれていますね。
ただ、よく見るとAIに学習させるにはまだ問題があります。
- 文字データ(馬名、騎手名など)がそのまま入っている
- 性齢は「牡2」のように性別と年齢が混ざっている
- 馬体重は「452(-4)」のように体重と増減が一緒になっている
- タイムは「1:09.5」のような文字列形式
こういった「人間には読みやすいけど、コンピュータには扱いにくいデータ」を、次回のデータ前処理で整えていきます。
まとめ
今回は、競馬予想AI作成の第一歩として、以下のことを行いました。
- ✅ Google Colab でPython実行環境を構築
- ✅ Google Drive をマウントしてデータを永続保存
- ✅ スクレイピング でnetkeibaからレース結果データを収集
- ✅ 取得したデータを CSV形式 で保存
これで、AIに学習させるための「材料」が手に入りました。
でも、このデータはまだ「生の状態」です。文字データが混ざっていたり、欠損値があったりと、機械学習モデルがそのまま理解できる形にはなっていません。
次回は、この生データを「AIが理解できる形」に変換するデータ前処理について解説します。ここが実は一番重要で、AIの精度を大きく左右する工程です。